AWS認定資格 WEB問題集&徹底解説
AIプラクティショナー
本サイトについて
AWS認定AIプラクティショナー(AWS Certified AI Practitioner:AIF-C01)の問題をカテゴリーやサービス毎に掲載しています。
全問解説付きなので、問題を解きながらAWSの各サービスについて理解を深めることができます。
ぜひ当サイトで効率的よく学習を進めてください。
会員機能をご利用頂くと、成績表や間違えた問題のみを表示できます。
スマホアプリのように当サイトへアクセスするために、ホーム画面に追加しておくと便利です。
スマホのホーム画面に登録する方法は?
本サイトの特徴
- 高い合格率本サイト利用者の約96%が合格
- 豊富な問題数と出題範囲の網羅500問の問題を掲載。AWSサービス毎に問題の絞り込みも可能
- 豊富な学習サポート機能
成績表や未回答問題の絞り込みなど学習サポート機能が充実
学習サポート機能を使ったおすすめの勉強方法- 豊富な実績
他資格を含め累計180,000人以上が本サイトで学習大手企業様において研修の副教材としてもご利用頂いております- 各AWSサービスの詳細な解説
- 継続的な問題の見直し
問題の評価結果を元に継続的な内容の見直しを実施AWSはサービス内容の変更も多いため継続的な問題の見直しを実施- 低価格な投資
他と比較して半値以下の価格。会員登録なしで10問、無料会員で50問利用可能
問題数制限なしの プレミアム会員 は無料トライアル期間あり内容にご満足できない場合、3クリックで解約可能ですので是非お気軽にお試しください
広告を出しておらず資格数も絞っているため低価格を実現しております(※)記載の内容は2026年1月時点となります。合格率の集計期間は2025年1月~2026年1月(プレミアム会員かつ問題回答率70%以上の利用者のみ集計。プレミアム会員解約時にアンケートのご協力をお願いしています)。会員数累計は無料会員を含みます。無料問題
まずは無料問題をお試しください。
No.11 以降は会員登録(無料)が必要です。
会員登録者数の推移
AWS問題集サイトでは、利用者数 No.1 です。
(※)他資格を含めた登録者数です
メディア掲載
充実の学習サポート機能
学習サポート機能の詳細はこちら
学習サポート機能を使ったおすすめの勉強方法では、科学的に正しい勉強方法を参考に、効率的な勉強方法を紹介しています。成績表 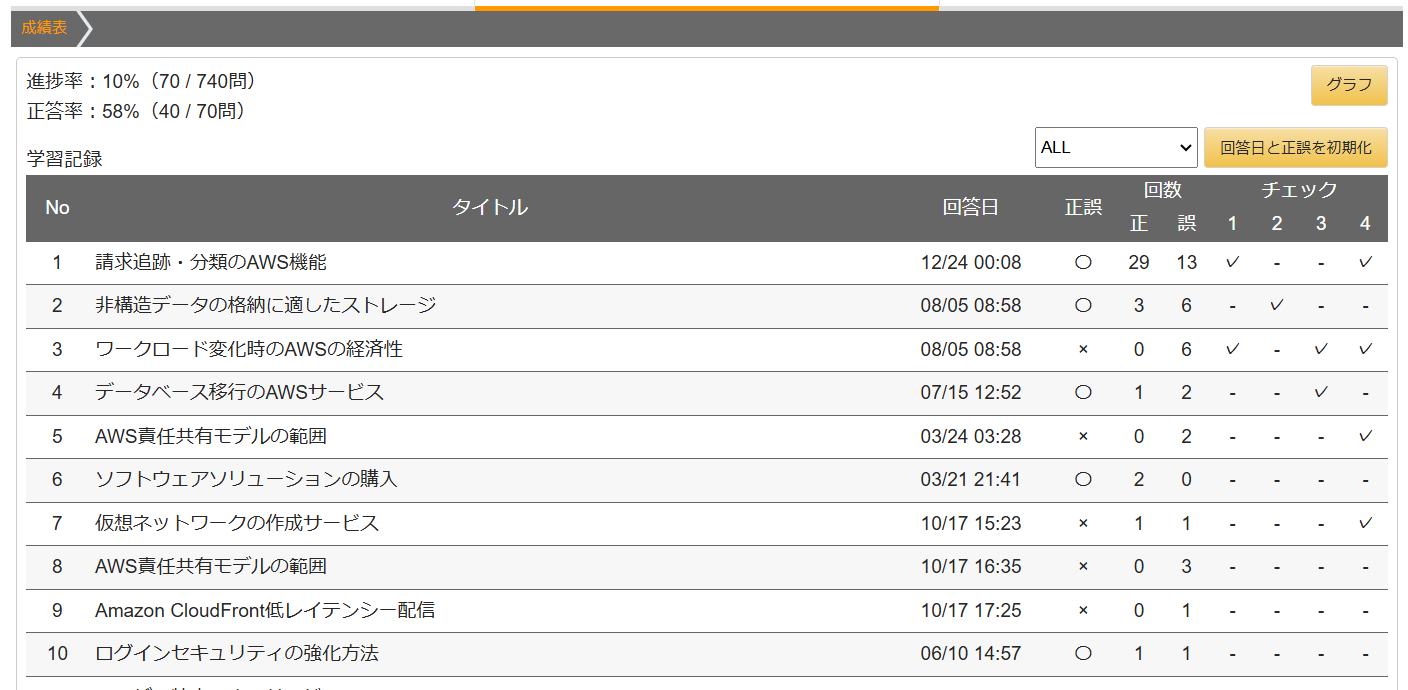
進捗率(成績表 > グラフ) 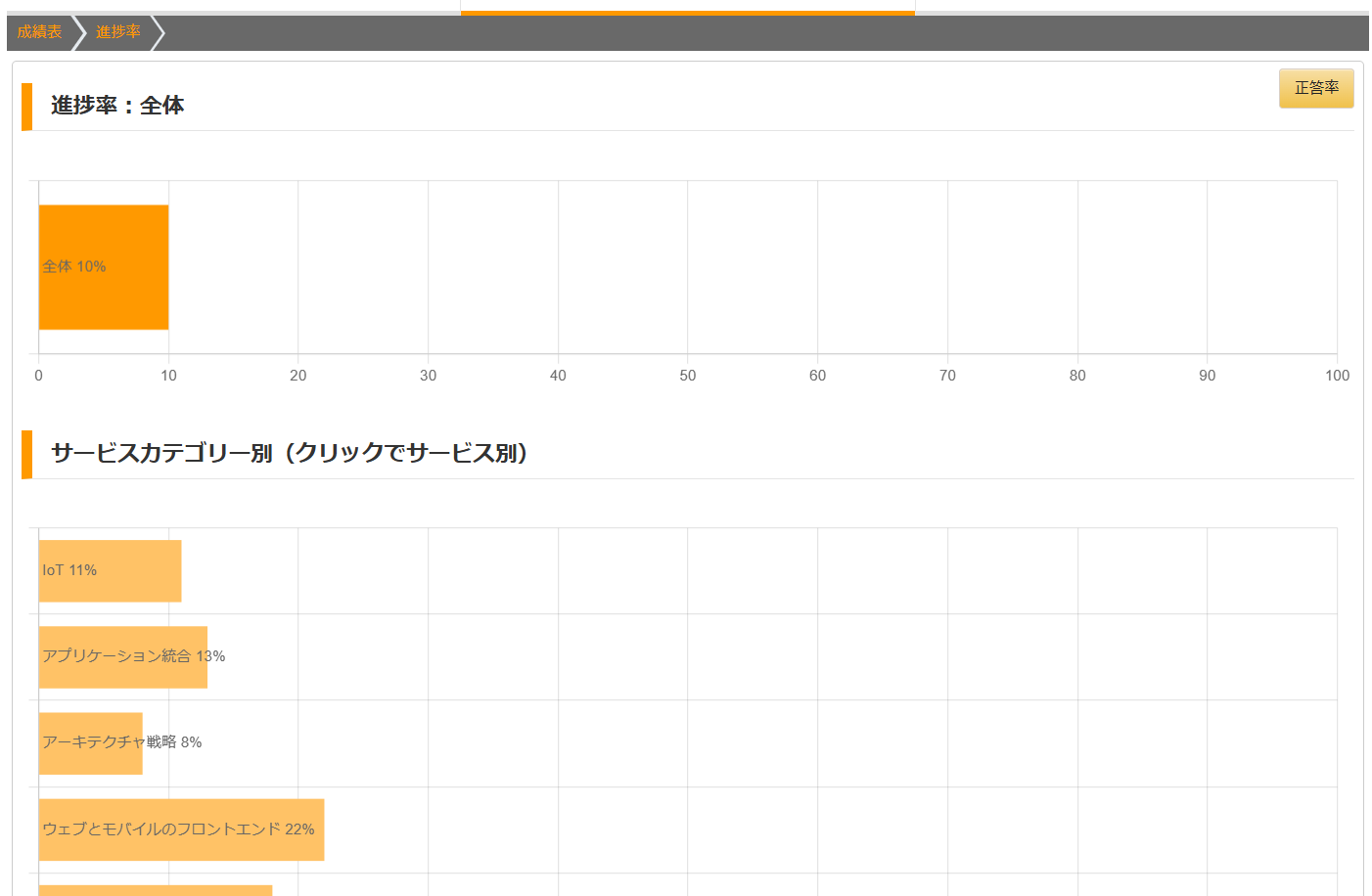
正答率(成績表 > グラフ) 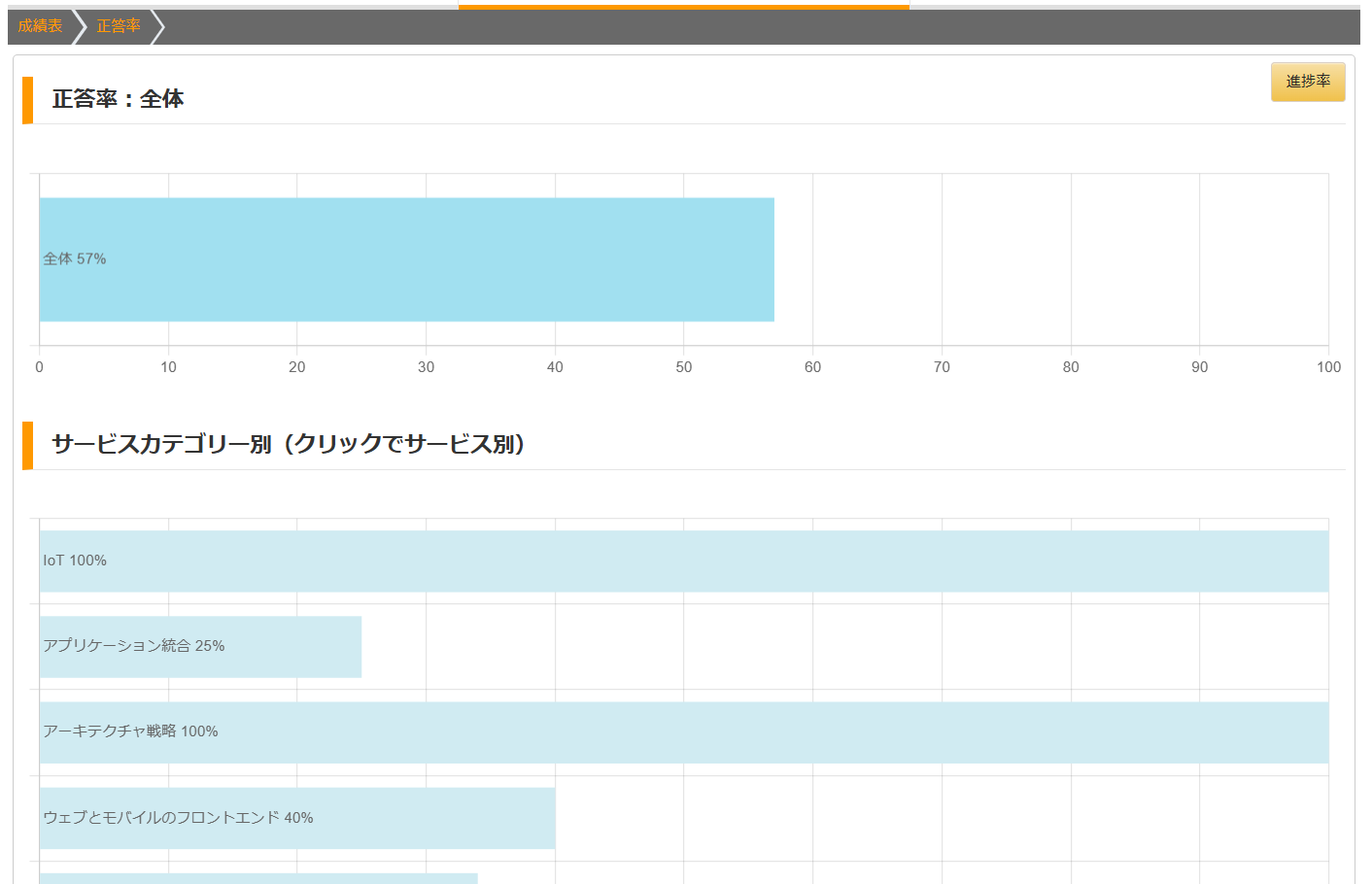
AWS認定 AIプラクティショナーとは?AWS認定資格とはどんな資格なのでしょうか?
また、その中でもAIプラクティショナーとは、どういった位置づけの資格になるのでしょうか?
ここでは、そういった疑問に解答してきたいと思います。
目次AWS認定 AIプラクティショナー(AIF) 試験とは?
AWS Certified AI Practitioner(AIF) 試験は、特定の職務に関係なく、AI/ML、生成 AI テクノロジー、関連する AWS のサービスとツールに関する総合的な知識を効果的に実証できる個人を対象としています。
どんな能力があることを証明できる?
- 一般的な、また AWS 上での、AI、ML、生成 AI の概念、手法、戦略についての知識
- AI/ML と生成 AI テクノロジーの適切な使用についての知識
- 特定のユースケースへの適用に適した AI/ML テクノロジーの種類を見極める知識
- AI、ML、生成 AI テクノロジーを責任を持って使用することが出来る知識
推奨されるAWSの知識
- AWS の主要なサービス (Amazon EC2、Amazon S3、AWS Lambda、Amazon SageMaker など) と AWS の主要なサービスのユースケースに精通している
- AWS クラウドのセキュリティとコンプライアンスに関する AWS 責任共有モデルに精通している
- AWS リソースへのアクセスをセキュリティ保護および制御するための AWS Identity and Access Management (AWS IAM) に精通している
- AWS リージョン、アベイラビリティーゾーン、エッジロケーションの概念など、AWS グローバルインフラストラクチャに精通している
- AWS のサービス料金モデルに精通している
広告試験内容
AWSサービスの特性に関する問題や企業の課題解決に対してどのAWSサービスを利用するのが最適化など、より実務に近い内容も出題されます。
出題分野と比重分野 内容 比重 1 AIとMLの基礎 20% 2 生成AIの基礎 24% 3 基盤モデルの応用 28% 4 責任あるAIに関するガイドライン 14% 5 AIソリューションのセキュリティ、コンプライアンス、ガバナンス 14%
各分野で求められる知識-
第 1 分野: AI と ML の基礎
1.1: AI の基本的な概念と用語を説明する- 基本的な AI 用語 [AI、ML、深層学習、ニューラルネットワーク、コンピュータビジョン、自然言語処理 (NLP)、モデル、アルゴリズム、トレーニングと推論、バイアス、公平性、フィット、大規模言語モデル(LLM) など] を定義する。
- AI、ML、深層学習の類似点と相違点を説明する。
- さまざまな種類の推論 (バッチ、リアルタイムなど) について説明する。
- AI モデルに含まれるさまざまなタイプのデータ (ラベル付きとラベルなし、表形式、時系列、画像、テキスト、構造化データと非構造化データなど) について説明する。
- 教師あり学習、教師なし学習、強化学習について説明する。
1.2: AI の実用的なユースケースを特定する- AI/ML が価値を提供できる応用分野 (人間の意思決定の支援、ソリューションのスケーラビリティ、オートメーションなど) を認識する。
- AI/ML ソリューションが適切でない場合 (費用対効果の分析、予測ではなく特定の結果が必要な状況など) を特定する。
- 特定のユースケース (回帰、分類、クラスタリングなど) に適した ML 手法を判断する。
- 実際の AI 応用例 (コンピュータビジョン、NLP、音声認識、レコメンデーションシステム、不正検出、予測など) を特定する。
- AWS のマネージド AI/ML サービス (SageMaker、Amazon Transcribe、Amazon Translate、Amazon Comprehend、Amazon Lex、Amazon Pollyなど) の機能を説明する。
1.3: ML 開発ライフサイクルについて説明する- ML パイプラインの構成要素 [データ収集、探索的データ分析 (EDA)、データの前処理、特徴量エンジニアリング、モデルトレーニング、ハイパーパラメータのチューニング、評価、デプロイ、モニタリングなど] について説明する。
- ML モデルのソース (オープンソースの事前トレーニング済みモデル、カスタムモデルのトレーニングなど) を理解する。
- 本番環境でモデルを使用する方法 (マネージド API サービス、セルフホストAPI など) を説明する。
- ML パイプラインの各ステージに関連する AWS のサービスと機能(SageMaker、Amazon SageMaker Data Wrangler、Amazon SageMakerFeature Store、Amazon SageMaker Model Monitor など) を特定する。
- ML 運用 (MLOps) の基本概念 (実験、反復可能なプロセス、スケーラブルなシステム、技術的負債の管理、本番稼働の準備、モデルモニタリング、モデルの再トレーニングなど) を理解する。
- ML モデルを評価するためのモデルパフォーマンスメトリクス [正解率、ROC 曲線下面積 (AUC)、F1 スコアなど] とビジネスメトリクス [ユーザーあたりのコスト、開発コスト、顧客からのフィードバック、投資収益率(ROI) など] を理解する。
-
第 2 分野: 生成 AI の基礎
2.1: 生成 AI の基本概念を説明する- 生成 AI の基礎となる概念 (トークン、チャンク化、埋め込み表現、ベクター、プロンプトエンジニアリング、トランスフォーマーベースのLLM、基盤モデル、マルチモーダルモデル、拡散モデルなど) を理解する。
- 生成 AI モデルの潜在的なユースケース (画像、動画、音声の生成、要約、チャットボット、翻訳、コード生成、カスタマーサービスエージェント、検索、レコメンデーションエンジンなど) を特定する。
- 基盤モデルのライフサイクル (データ選択、モデル選択、事前トレーニング、ファインチューニング、評価、デプロイ、フィードバックなど) を説明する。
2.2: ビジネス上の問題解決に生成 AI を使用する場合の可能性と限界を理解する- 生成 AI のメリット (適応性、応答性、シンプルさなど) を説明する。
- 生成 AI ソリューションのデメリット (ハルシネーション、解釈可能性、不正確さ、非決定性など) を特定する。
- さまざまな要因を理解して、適切な生成 AI モデル (モデルタイプ、パフォーマンス要件、機能、制約、コンプライアンスなど) を選択する。
- 生成 AI アプリケーションのビジネス価値とメトリクス (クロスドメインのパフォーマンス、効率、コンバージョン率、ユーザーあたりの平均収益、正解率、顧客生涯価値など) を見極める。
2.3: 生成 AI アプリケーションを構築するための AWS インフラストラクチャとテクノロジーについて説明する- 生成 AI アプリケーションを開発するための AWS のサービスと機能 (AmazonSageMaker JumpStart、Amazon Bedrock、PartyRock、Amazon BedrockPlayground、Amazon Q など) を特定する。
- AWS の生成 AI サービスを使用してアプリケーションを構築するメリット(アクセシビリティ、参入障壁の低さ、効率性、費用対効果、市場投入までのスピード、ビジネス目標の達成能力など) を説明する。
- 生成 AI アプリケーションの AWS インフラストラクチャの利点(セキュリティ、コンプライアンス、責任、安全性など) を把握する。
- AWS の生成 AI サービスの、コストに対するトレードオフ (応答性、可用性、冗長性、パフォーマンス、リージョン展開、トークンベースの価格設定、プロビジョンスループット、カスタムモデルなど) を把握する。
-
第 3 分野: 基盤モデルの応用
3.1: 基盤モデルを使用するアプリケーションの設計上の考慮事項を説明する- 事前トレーニング済みモデルを選ぶための選択基準 (コスト、モダリティ、レイテンシー、多言語、モデルサイズ、モデルの複雑さ、カスタマイズ、入力/出力の長さなど) を明確にする。
- 推論パラメータがモデルの応答に与える影響 (温度、入出力の長さなど) を理解する。
- 検索拡張生成 (RAG) を定義し、ビジネスにおけるその活用方法 (AmazonBedrock、ナレッジベースなど) を説明する。
- ベクターデータベースへの埋め込みの保存に役立つ AWS のサービス[Amazon OpenSearch Service、Amazon Aurora、Amazon Neptune、Amazon DocumentDB (MongoDB 互換)、Amazon RDS for PostgreSQL など]を特定する。
- 基盤モデルをカスタマイズするためのさまざまなアプローチ (事前トレーニング、ファインチューニング、状況に応じた学習、RAG など) のコスト面でのトレードオフを説明する。
- マルチステップのタスクにおけるエージェント (Amazon Bedrock のエージェントなど) の役割を理解する。
3.2: 効果的なプロンプトエンジニアリング手法を選択する- プロンプトエンジニアリングの概念と構成 (コンテキスト、指示、ネガティブプロンプト、モデルの潜在空間など) を説明する。
- プロンプトエンジニアリングの手法 (思考の連鎖、ゼロショット、シングルショット、フューショット、プロンプトテンプレート) を理解する。
- プロンプトエンジニアリングの利点とベストプラクティス (応答品質の向上、実験、ガードレール、発見、具体性と簡潔さ、複数のコメントの使用)を理解する。
- プロンプトエンジニアリングの潜在的なリスクと限界 (露出、ポイズニング、ハイジャック、ジェイルブレイクなど) を定義する。
3.3: 基盤モデルのトレーニングとファインチューニングのプロセスを説明する- 基盤モデルのトレーニングの重要な要素 (事前トレーニング、ファインチューニング、継続的な事前チューニングなど) を説明する。
- 基盤モデルをファインチューニングするための方法 (指示のチューニング、特定の分野へのモデルの適応、転移学習、継続的な事前トレーニングなど)を定義する。
- 基盤モデルをファインチューニングするためのデータの準備方法 [データキュレーション、ガバナンス、サイズ、ラベル付け、代表性、人間からのフィードバックによる強化学習 (RLHF) など] を説明する。
3.4: 基盤モデルのパフォーマンスを評価する方法を説明する- 基盤モデルのパフォーマンスを評価する手法 (人間による評価、ベンチマークデータセットなど) を理解する。
- 基盤モデルのパフォーマンスを評価するための関連メトリクス [RecallOriented Understudy for Gisting Evaluation (ROUGE)、Bilingual EvaluationUnderstudy (BLEU)、BERTScore など] を特定する。
- 基盤モデルがビジネス目標 (生産性、ユーザーエンゲージメント、タスクエンジニアリングなど) を効果的に満たしているかどうかを判断する。
-
第 4 分野: 責任ある AI に関するガイドライン
4.1: 責任ある AI システムの開発について説明する- 責任ある AI の特徴 (バイアス、公平性、包括性、堅牢性、安全性、信憑性など) を特定する。
- 責任ある AI の特徴を特定するためのツール (Amazon Bedrock のガードレールなど) の使用方法を理解する。
- モデルを選択するうえでの責任ある慣行 (環境への配慮、持続可能性、道徳的主体性など) を理解する。
- 生成 AI を使用する際の法的リスク (知的財産権侵害の申し立て、偏ったモデル出力、顧客の信頼喪失、エンドユーザーリスク、ハルシネーションなど) を明確にする。
- データセットの特徴 (包括性、多様性、キュレートされたデータソース、バランスの取れたデータセットなど) を特定する。
- バイアスと分散の影響 (人口統計グループへの影響、不正確さ、オーバーフィット、アンダーフィットなど) を理解する。
- バイアス、信頼性、真実性を検出およびモニタリングするためのツール[ラベル品質の分析、人間による監査、サブグループ分析、AmazonSageMaker Clarify、SageMaker Model Monitor、Amazon Augmented AI(Amazon A2I) など] について説明する。
4.2: 透明性の高い説明可能なモデルの重要性を認識する- 透明性の高い説明可能なモデルと、透明性の低い説明不可能なモデルの違いを理解する。
- 透明で説明可能なモデルを識別するためのツール (Amazon SageMakerModel Cards、オープンソースモデル、データ、ライセンスなど) を把握する。
- モデルの安全性と透明性の間のトレードオフを特定する (解釈可能性とパフォーマンスを測定するなど)。
- 説明可能な AI のための人間中心設計の原則を理解する。
-
第 5 分野: AI ソリューションのセキュリティ、コンプライアンス、ガバナンス
5.1: AI システムを保護する方法を説明する- AI システムを保護するための AWS のサービスと機能 (IAM ロール、ポリシー、アクセス許可、暗号化、Amazon Macie、AWS PrivateLink、AWS 責任共有モデルなど) を特定する。
- ソース引用とデータ出典の文書化の概念 (データリネージ、データのカタログ化、SageMaker Model Cards など) を理解する。
- 安全なデータエンジニアリングのベストプラクティス (データ品質の評価、プライバシー強化技術の実装、データアクセス制御、データの完全性など)を説明する。
- AI システムのセキュリティとプライバシーに関する考慮事項(アプリケーションセキュリティ、脅威検出、脆弱性管理、インフラストラクチャ保護、プロンプトインジェクション、保管中および転送中の暗号化など) を理解する。
5.2: AI システムのガバナンスとコンプライアンス規制を認識する- AI システムの規制コンプライアンス基準 [国際標準化機構 (ISO)、System and Organization Controls (SOC)、アルゴリズム説明責任法] を特定する。
- ガバナンスと規制コンプライアンスを支援する AWS のサービスと機能(AWS Config、Amazon Inspector、AWS Audit Manager、AWS Artifact、AWS CloudTrail、AWS Trusted Advisor など) を特定する。
- データガバナンス戦略 (データライフサイクル、ログ記録、レジデンシー、モニタリング、観察、保持など) を説明する。
- ガバナンスプロトコル (ポリシー、レビューサイクル、レビュー戦略、生成 AI セキュリティスコーピングマトリックスなどのガバナンスフレームワーク、透明性基準、チームトレーニング要件など) に従うためのプロセスを説明する。
広告受験概要(試験形式・試験場所・試験日程・受験料・合格基準・有効期限)
AWS認定 AIプラクティショナー(AIF)の試験概要は以下の通りです。
試験形式試験は、テストセンターまたはオンラインでPC操作で行います。
問題数は65問、試験時間は90分で、全て選択問題になります。
1問あたり1分20秒ですので、時間的には余裕をもって解けるかと思います。
試験場所テストセンターの場合は、受験申し込みの際に以下のような感じで郵便番号を入力すると、最寄りのテストセンターが表示されます。
 試験日程
試験日程テストセンターにより異なります。
毎日行っているところもあれば、平日のみのテストセンターもありました。※ただし、不合格で再受験する場合は、14日間待つ必要があります。受験料15,000円(税別)
※試験区分により異なります合格基準70%
※配点は公開されていませんが、1000点満点で700点が最低合格ラインとなります。有効期限3年間
広告 - 豊富な学習サポート機能